
Hi! 😊 I’m a PhD student in Information Science at the University of North Texas, working at the intersection of Human-Centered AI, NLP, and HCI. My research focuses on evaluating and understanding the reasoning capacities of Large Language Models (LLMs) and Vision-Language Models (VLMs), particularly in how these systems handle cultural context, multilingual understanding, and complex reasoning tasks.
My current research investigates reasoning evaluation in foundation models, examining how LLMs and VLMs perform across diverse linguistic and cultural contexts. I’m particularly interested in understanding the limitations and capabilities of these models when reasoning about information from underrepresented languages and communities in the Global South. Through systematic evaluation frameworks, I aim to identify gaps in model reasoning abilities and develop more robust benchmarks that account for cultural and linguistic diversity.
My broader research interests lie at the intersection of AI ethics, multilingual NLP, and participatory design. I explore questions around formality and cultural biases in large language models, AI policy-making in developing countries, and co-design methodologies that center the voices of underrepresented users. Through rigorous evaluation and human-centered design, I work toward building more equitable, transparent, and accountable AI systems that serve diverse global communities.
Previously, I worked as an HCI researcher at the Design, Inclusion & Access Lab (DIAL) at North South University with Dr. Nova Ahmed, investigating challenges faced by women in computing and studying AI ethics frameworks for South Asian contexts. I also conducted NLP research as a senior research assistant with Dr. M. Rashedur Rahman on Bengali natural language generation, and completed a predoctoral fellowship with the Fatima Fellowship mentored by Benjamin Muller, investigating cultural biases in multilingual generative models.
I graduated with a B.Sc. in Computer Science and Engineering from North South University in 2020, where my thesis focused on building deep learning models for Bengali question answering systems. During my undergraduate years, I participated in Google Summer of Code twice—in 2019 with TensorFlow Hub and in 2018 with the Berkman Klein Center for Internet & Society at Harvard.
When I’m not immersed in research, I enjoy watching anime, reading manga or books, and taking care of my cats. 🐈⬛
[Note] I am actively applying for Research Internships and looking for collaborations.
🔥 News
- 2025.11: 🎉🎉 Long paper accepted at ACM CHI 2026 from ACM ToCHI Journal!
- 2025.10: 🎉🎉 Long paper accepted at Workshop on Secure and Safe AI Agents, IEEE Big Data 2025!
- 2025.09: 🎉🎉 Long paper accepted at ACM ToCHI Journal!
- 2025.08: 🎉🎉 I joined University of North Texas as a PhD student!
- 2024.12: 🎉🎉 Long paper accepted at ICTD 2024! Presenting in Nairobi, Kenya.
- 2024.10: 🎉🎉 Paper accepted at UbiComp 2024!
- 2023.10: 🎉🎉 Paper accepted at EMNLP 2023 Findings!
- 2023.09: 🎉🎉 Paper accepted at MM-NLG Workshop (INLG 2023)!
- 2023: 🏅🏅 Our paper “Making ethics at home in Global CS Education” received Best Journal Paper Award at ACM COMPASS 2023!
📝 Publications
For a complete list of publications, please visit my Google Scholar.
💬 Natural Language Processing

Adversarial Misdirection: Probing & Visualizing Cross-Modal Reasoning Vulnerabilities in Vision–Language Models. Accepted manuscript (to appear).
Tasmiah Tahsin Mayeesha, Pretom Roy Ovi, Sharad Sharma
- We introduce a framework for studying adversarial attacks on VLM reasoning capabilities, revealing that spatial reasoning is particularly vulnerable with a 20% attack success rate and 16% accuracy drop under low-cost prompt manipulations.
📑 Click to see abstract
As multimodal AI systems increasingly underpin perception and reasoning in interactive environments, understanding their robustness has become a critical research frontier. Vision-language models (VLMs) are rapidly emerging as core perceptual and cognitive components in autonomous agents capable of multi-step reasoning, planning, and decision-making across complex, dynamic environments. Despite significant progress in adversarial robustness research for single-modality systems such as text or vision models, the vulnerabilities of VLMs—and particularly of VLM-based agents to cross-modal adversarial attacks that target reasoning processes remain underexplored. This paper introduces an exploratory framework for systematically studying adversarial interventions that disrupt the reasoning capabilities of VLMs. We focus on low-cost, feasible perturbations such as prompt injections and instruction manipulations that maintain surface plausibility while subtly interfering with compositional reasoning chains. Our evaluation on 200 carefully curated visual reasoning questions across four reasoning categories (counting, comparison, relational, and spatial) reveals an overall attack success rate of 9.5% and that spatial reasoning is particularly vulnerable to misdirection attacks, with accuracy dropping by 16% and a 20% attack success rate. We find that modern VLMs like GPT-4o-mini demonstrate varying robustness and accuracy across reasoning types. By framing adversarial attacks as disruptions to reasoning rather than perception alone, this work offers a foundation for analyzing and mitigating reasoning failures in multimodal systems intended for safety-critical and human–AI interaction contexts.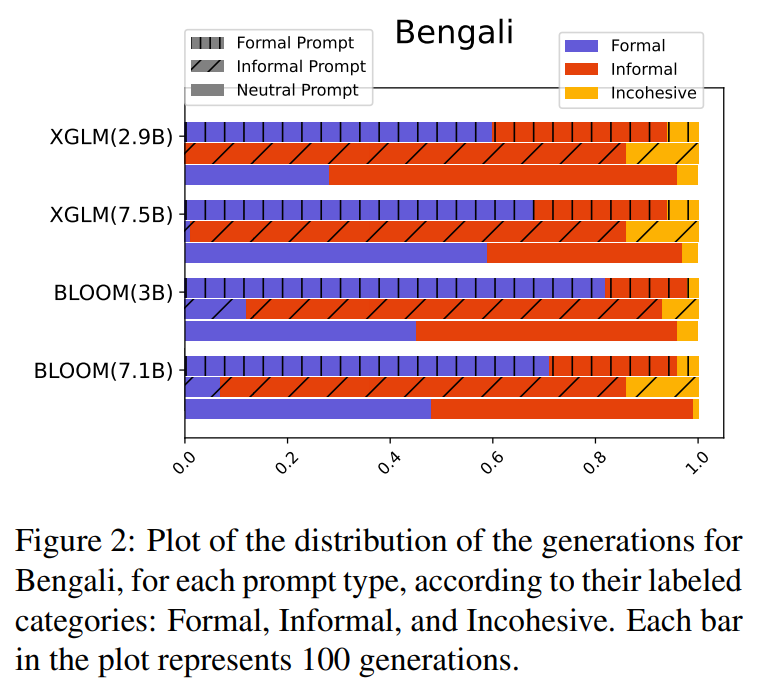
Asim Ersoy, Gerson Vizcarra, Tasmiah Tahsin Mayeesha, Benjamin Muller
- We analyze formality distributions in XGLM and BLOOM’s predictions across 5 languages, revealing diverse behaviors and significant cultural biases in multilingual generative models’ handling of formality.
📑 Click to see abstract
Multilingual generative language models (LMs) are increasingly fluent in a large variety of languages. Trained on the concatenation of corpora in multiple languages, they enable powerful transfer from high-resource languages to low-resource ones. However, it is still unknown what cultural biases are induced in the predictions of these models. In this work, we focus on one language property highly influenced by culture: formality. We analyze the formality distributions of XGLM and BLOOM's predictions, two popular generative multilingual language models, in 5 languages. We classify 1,200 generations per language as formal, informal, or incohesive and measure the impact of the prompt formality on the predictions. Overall, we observe a diversity of behaviors across the models and languages. For instance, XGLM generates informal text in Arabic and Bengali when conditioned with informal prompts, much more than BLOOM. In addition, even though both models are highly biased toward the formal style when prompted neutrally, we find that the models generate a significant amount of informal predictions even when prompted with formal text. We release with this work 6,000 annotated samples, paving the way for future work on the formality of generative multilingual LMs.
Visual Question Generation in Bengali
Mahmud Hasan, Labiba Islam, Jannatul Ruma, Tasmiah Tahsin Mayeesha, Rashedur Rahman
- We propose the first Bengali Visual Question Generation system with transformer-based models conditioned on images, categories, and answers, achieving strong performance on translated VQAv2.0 dataset.
📑 Click to see abstract
The task of Visual Question Generation (VQG) is to generate human-like questions relevant to the given image. As VQG is an emerging research field, existing works tend to focus only on resource-rich language such as English due to the availability of datasets. In this paper, we propose the first Bengali Visual Question Generation task and develop a novel transformer-based encoder-decoder architecture that generates questions in Bengali when given an image. We propose multiple variants of models - (i) image-only: baseline model of generating questions from images without additional information, (ii) image-category and image-answer-category: guided VQG where we condition the model to generate questions based on the answer and the category of expected question. These models are trained and evaluated on the translated VQAv2.0 dataset. Our quantitative and qualitative results establish the first state of the art models for VQG task in Bengali and demonstrate that our models are capable of generating grammatically correct and relevant questions.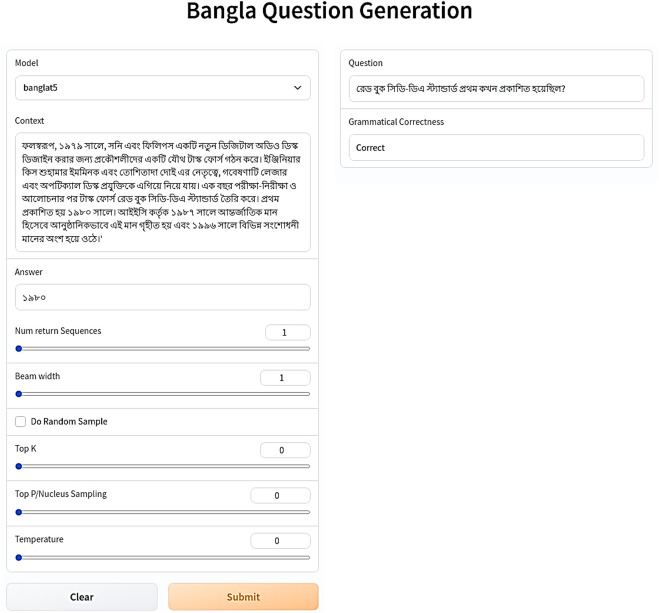
Transformer Based Answer-Aware Bengali Question Generation
Jannatul Ferdous Ruma, Tasmiah Tahsin Mayeesha, Rashedur M. Rahman
- We develop fine-tuned BanglaT5 models for Bengali question generation achieving 35.77 RougeL F-score, generating 98% grammatically accurate questions with released code, dataset, and models.
📑 Click to see abstract
Question generation (QG), the task of generating questions from text or other forms of data, a significant and challenging subject, has recently attracted more attention in natural language processing (NLP) due to its vast range of business, healthcare, and education applications through creating quizzes, Frequently Asked Questions (FAQs) and documentation. Most QG research has been conducted in languages with abundant resources, such as English. However, due to the dearth of training data in low-resource languages, such as Bengali, thorough research on Bengali question generation has yet to be conducted. In this article, we propose a system for producing varied and pertinent Bengali questions from context passages in natural language in an answer-aware input format using a series of fine-tuned text-to-text transformer (T5) based models. During our studies with various transformer-based encoder-decoder models and various decoding processes, along with delivering 98% grammatically accurate questions, our fine-tuned BanglaT5 model had the highest 35.77 F-score in RougeL and 38.57 BLEU-1 score with beam search.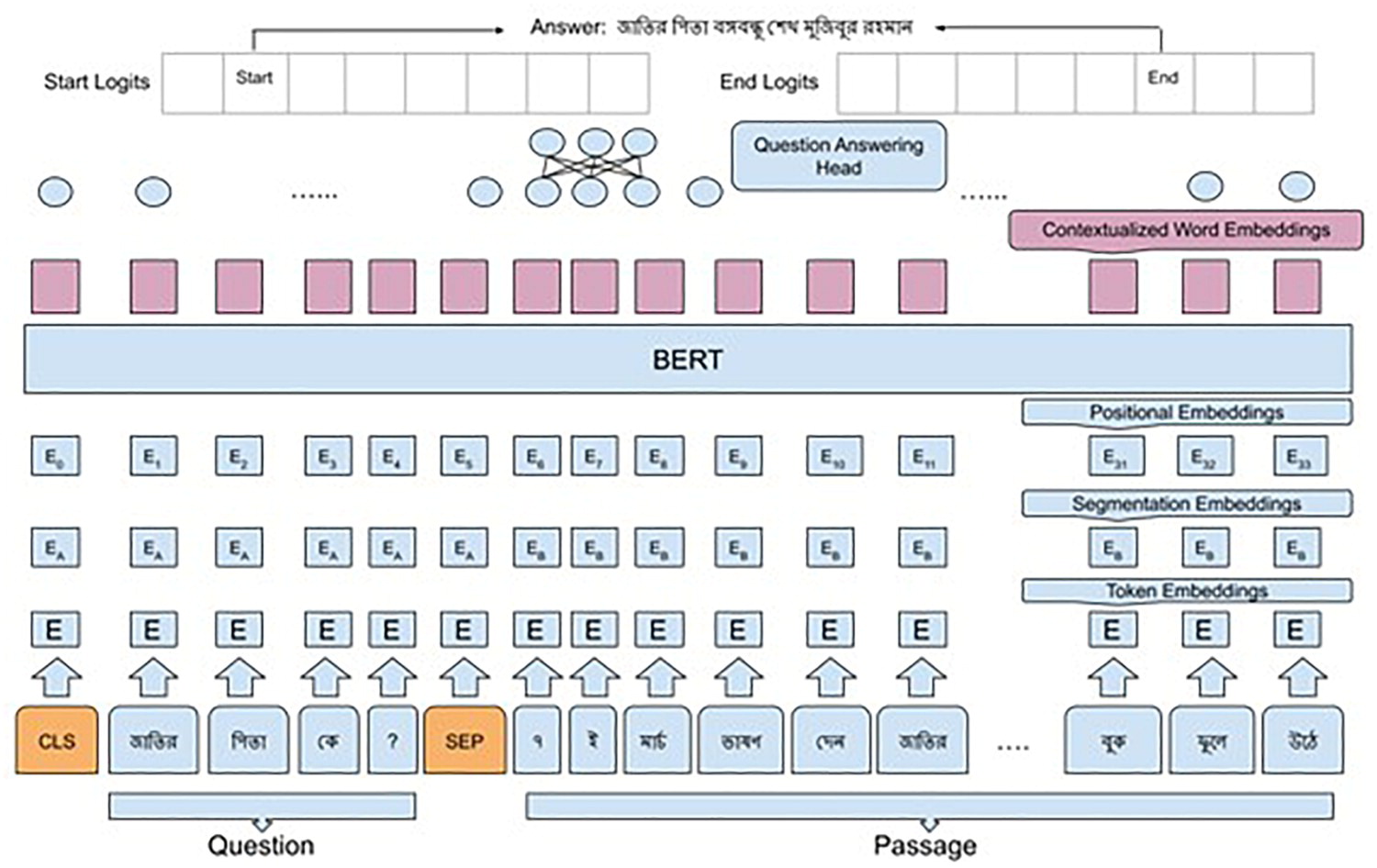
Deep learning based question answering system in Bengali
Tasmiah Tahsin Mayeesha, Abdullah Md Sarwar, Rashedur M Rahman
- We establish the first end-to-end benchmark for Bengali question answering by training transformer-based models on a translated SQuAD 2.0 dataset, introducing a culturally grounded human-annotated evaluation set, and reporting the first human baseline scores.
📑 Click to see abstract
Recent advances in the field of natural language processing has improved state-of-the-art performances on many tasks including question answering for languages like English. Bengali language is ranked seventh and is spoken by about 300 million people all over the world. But due to lack of data and active research on QA similar progress has not been achieved for Bengali. Unlike English, there is no benchmark large scale QA dataset collected for Bengali, no pretrained language model that can be modified for Bengali question answering and no human baseline score for QA has been established either. In this work we use state-of-the-art transformer models to train QA system on a synthetic reading comprehension dataset translated from one of the most popular benchmark datasets in English called SQuAD 2.0. We collect a smaller human annotated QA dataset from Bengali Wikipedia with popular topics from Bangladeshi culture for evaluating our models. Finally, we compare our models with human children to set up a benchmark score using survey experiments.🛡️ AI Safety, Ethics & Policy
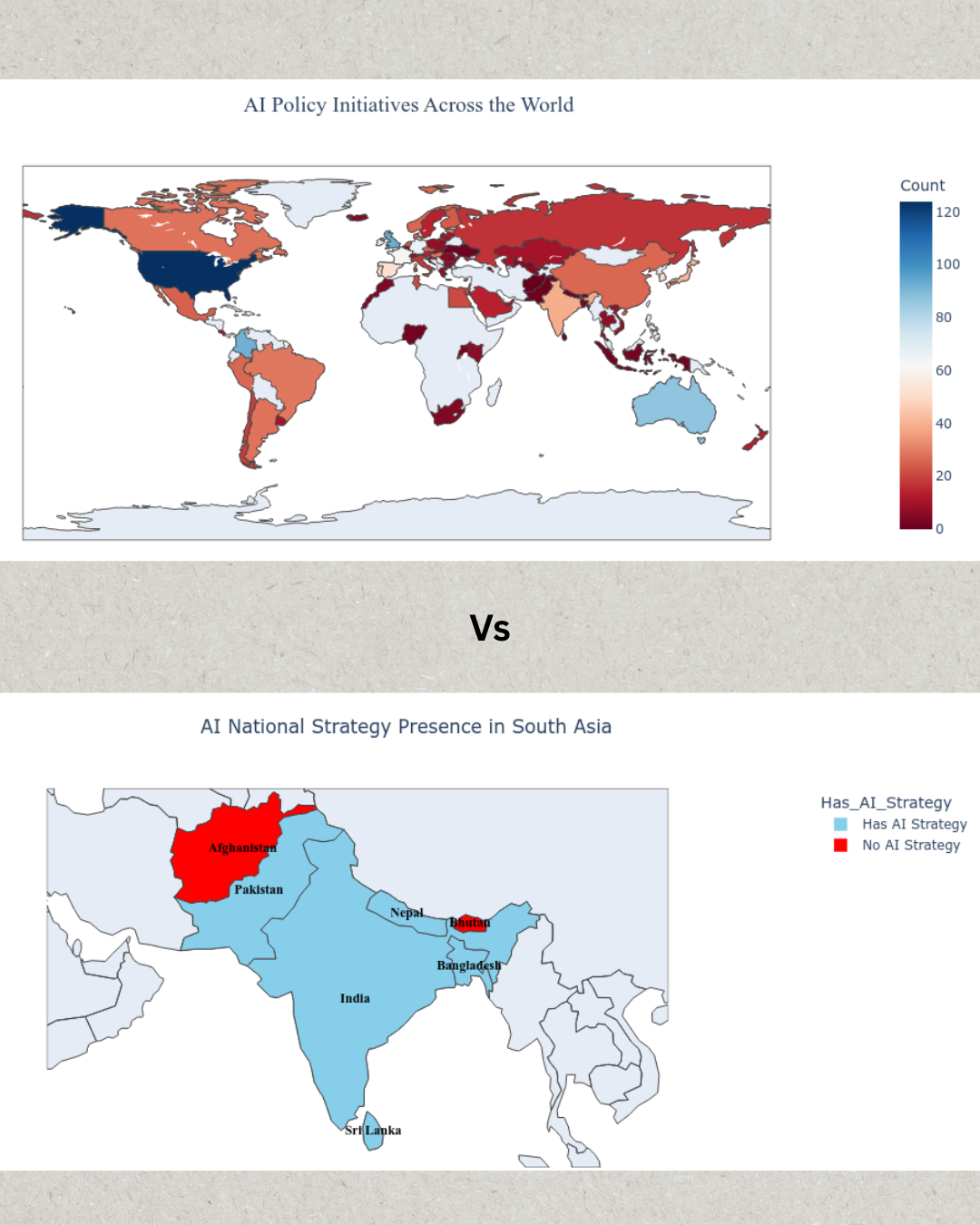
Navigating the Unknown: Regulation of Generative AI in South Asia
Tasmiah Tahsin Mayeesha and others
- Through 32 stakeholder interviews across four South Asian countries, we explore challenges in regulating generative AI and propose contextualized frameworks addressing the region’s unique social, legal, and infrastructural needs.
📑 Click to see abstract
Generative AI technologies, such as ChatGPT, Midjourney, and DALL-E, have revolutionized multiple sectors like agriculture, healthcare, and finance with their capability to produce advanced results. However, these technologies have the potential to cause harm in the form of spreading misinformation, manipulation of public sentiment, and creating discriminatory content that perpetuates harm toward a variety of groups. These risks are especially concerning in South Asia, where AI regulation remains nascent, and many internet users lack social media literacy. Without effective regulation, the harmful impacts of generative AI on social media could be amplified. This study explores how South Asian countries have developed policies to regulate generative AI and identifies the region-specific challenges in moderating AI-generated content. The study reviews existing literature on AI regulation principles in Asia and draws insights through semi-structured interviews with 32 stakeholders from four South Asian countries, including academic researchers, industry professionals, government officials, and legal experts. Using a content analysis of interview transcripts, the work explores social, legal, and infrastructural challenges of managing generative AI. Respondents highlighted the hazards of social media's use of generative AI and emphasized the need for contextualized rules that would be sensitive to the diverse groups found in South Asian society. Thus, the study presents comparative analysis of regulation frameworks and addresses ways of creating responsible regulation of generative AI in the region in a manner that addresses the complex nature of AI's prospects and challenges in South Asian society.
AI4Bangladesh: AI Ethics for Bangladesh - Challenges, Risks, Principles, and Suggestions
Tasmiah Tahsin Mayeesha, Farzana Islam, Nova Ahmed
- We present findings from 32 qualitative interviews examining AI ethics challenges in Bangladesh’s emerging AI ecosystem, proposing seven ethics principles and a roadmap for transparent, accountable, and fair AI development.
📑 Click to see abstract
In recent times, the term AI ethics caught the attention among the academics, legislators, developers, and among AI users to promote ethical AI development. While countries in the North have led the way in discussions about the direction of ethical and responsible artificial intelligence development and deployment, perspectives from developing countries like Bangladesh are underrepresented. Based on 32 qualitative interviews with different stakeholders, including machine learning practitioners, academic researchers, and policymakers in the emerging AI ecosystem in Bangladesh, this work closely examines the ongoing challenges and opportunities to ensure AI ethics in Bangladesh with emerging AI usage. In Bangladesh, the government has not yet fully implemented measures to empower citizens with AI-related skills, policies, resources, and data ethics, and a significant portion of the population lacks knowledge in AI. In this paper, we are presenting the findings of AI4Bangladesh project that intend to create the roadmap for ethical AI in Bangladesh. We outline the core challenges, present situation, and risks of AI for Bangladesh; propose seven AI ethics principles, and offer suggestions to ensure a transparent, accountable, and fair AI ecosystem for Bangladesh.
Making ethics at home in Global CS Education: Provoking stories from the Souths
Marisol Wong-Villacres, Cat Kutay, Shaimaa Lazem, Nova Ahmed, Cristina Abad, Cesar Collazos, Shady Elbassuoni, Farzana Islam, Deepa Singh, Tasmiah Tahsin Mayeesha, Martin Mabeifam Ujakpa, Tariq Zaman, Nicola J Bidwell
🏆 Best Journal Paper Award
- We examine how CS ethics education should account for diverse cultural contexts across the Global South, drawing on experiences from 46 educators and 9 practitioners to inform ACM curriculum revisions.
📑 Click to see abstract
University courses and curricula on the ethics of computing are increasing, yet there are few studies about how CS programs should account for the diverse ways ethical dilemmas and approaches to ethics are situated in cultural, philosophical and governance systems, religions and languages. This paper seeks to prompt conversations about CS education that accounts for ethics in the Global Souths. We draw on the experiences and insights of 46 university educators and 9 practitioners, in Latin America, South Asia, Africa, the Middle east and Australian First Nations. Our modest study sought to inform revisions of the ACM's international curricular guidelines for the Society, Ethics and Professionalism knowledge area in undergraduate CS programs.- Ubicomp 2024 (XAI For U Workshop) Know Your Users: Towards Explainable AI in Bangladesh Farzana Islam, Tasmiah Tahsin Mayeesha, Nova Ahmed
👥 Human-Computer Interaction (HCI)
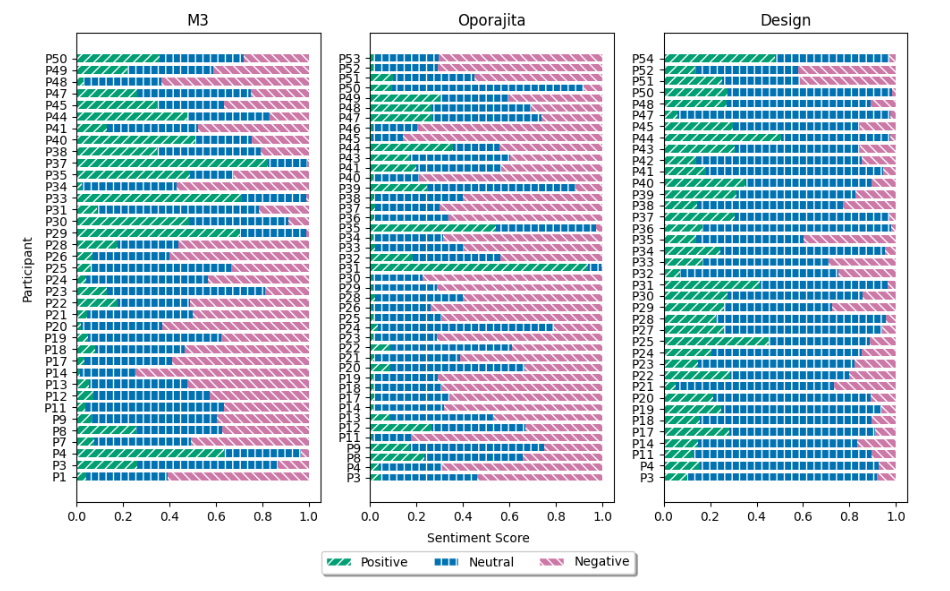
Nova Ahmed, Tasmiah Tahsin Mayeesha, Ifti Azad Abeer, Sumit Kumar Kar, Anik Saha, Anik Sinha, Sumaya Akter Ruhi, Md. Hussain Shahriar, Sumaya Yasmin, Nazmun Nahar, Syeda Shabnam Khan
- Using fictional inquiry and co-design workshops with 48 women computing students across Bangladesh, we explore barriers and solutions while reflecting on methodological approaches for culturally appropriate WiC research.
📑 Click to see abstract
Gender disparity in computing is a well-explored concern. To complement existing research, we use a non-intrusive exploration method of Fictional Inquiry. Followed by co-design workshop to explore solution approaches to increase women's participation in computing. The study involved n=48 women in computing (WiC) students in computing from 4 universities across Bangladesh. Participants shared their challenges and desired solutions which we analyzed using qualitative methods along with Natural Language Processing based tools to illustrate the problems from various perspectives while minimizing potential biases. The research team reflects on methodological decisions, policy implications, and the need for culturally and contextually appropriate tools and datasets to better support WiC research in resource-limited settings.
Nova Ahmed, Tasmiah Tahsin Mayeesha, Ifti Azad Abeer, Anik Sinha, Anik Saha
- Using fictional inquiry and co-design with 71 participants across Bangladesh, we identify three major elements for women’s success in computing: skill development, sense of belonging, and safety—providing guidelines for stakeholders and policymakers.
📑 Click to see abstract
The underrepresentation of women in computing in the workplace requires an understanding of the adequate elements needed for women to succeed in Bangladesh complementing the existing body of work. It uses a varied modality of communication Fictional inquiry (FI), where participants write letters to fictional characters followed by a Co-design of solutions. This research considers N=71 participants, 48 tertiary-level computer science and engineering students, and 23 stakeholders covering academics, computing professionals, and guardians of women in computing over a period of one and a half years. The study identifies three major elements for women in computing to succeed professionally: provision to improve skills and self-efficacy, ensuring ways to increase the sense of belonging, and providing transportation and safety aligning through the women's empowerment framework of Naila Kabeer. The required elements for success and empowerment show that a collaborative approach of support is required from families, institutes, and authorities from a regional perspective that can be of interest to researchers from the HCI, CSCW, and ICTD fields. This work is further expected to provide a guideline for stakeholders, policymakers, institutions, and families eager to ensure inclusive learning and growing space for women in computing.-
IEEE Region 10 Symposium (TENSYMP) 2025 Exploring the Social Barriers During Their Learning Pathways for Women in Computing (WiC) Nova Ahmed, Tasmiah Tahsin Mayeesha, Ifti Azad Abeer, Anik Saha, Anik Sinha
-
CSCW 2018 (Solidarity Across Borders Workshop ) Applying Text Mining to Protest Stories as Voice against Media Censorship Tasmiah Tahsin Mayeesha, Zareen Tasneem, Jasmin Jones, Nova Ahmed
🚀 Projects
-
Bengali Automatic Speech Recognition System, Huggingface Robust Speech Event, 2022. | [Model] | [Benchmark] - Fine-tuned Wav2vec2-xls-r model on OpenSLR Bangla Speech dataset with 200k+ samples, recognized as one of the best performing models for Bengali in the Huggingface Robust Speech Sprint.
-
Bengali GPT-2 Model, Huggingface Flax-Jax Event, 2021. | [Model] - Pre-trained GPT-2 model on Bengali corpus from mC4 (multilingual C4) dataset with fine-tuned variations including Bengali song lyrics generation.
-
Credit Card Recommender System, Software Engineering Course, 2018. | [Code] - Similarity-based recommendation model using geolocation and card-specific features from Bangladeshi banks, deployed with Django web app and Google Dialogflow chatbot.
-
Dobhashi - English-Bangla Machine Translation, Natural Language Processing Course, 2018. | [Report] - LSTM and transformer-based machine translation model trained on SUPARA Benchmark corpus, achieving BLEU score of 46.
-
News Article Network Visualization on Violence Against Women, 2017. | [Interactive Network] | [Code] - Network visualization exploring media coverage of harassment and violence against women cases. Featured by Fast.ai in “Deep Learning, Not just for Silicon Valley”.
📖 Educations
- 2024.08 - Present, Ph.D. in Information Science (Data Science Concentration), University of North Texas, Denton, Texas, USA.
- 2016 - 2020, B.Sc. in Computer Science and Engineering, North South University, Dhaka, Bangladesh.
💻 Research Experience
-
2026 - Present, Graduate Teaching Assistant, Data Science Department, University of North Texas
- 2025 - Present, Graduate Research Assistant, University of North Texas, supervised by Dr. Pretom Roy Ovi
- Evaluating reasoning capabilities of LLMs on logical puzzles and structured reasoning tasks
- Designing novel benchmarks for LLM logical and visual reasoning evaluation; analyzing failure modes and domain shift effects
- 2024 - 2025, NLP Researcher, EBLICT-Dream71 Virtual Private Assistant (VPA) Project (funded by Bangla.gov.bd), supervised by Mohammad Mamun Or Rashid
- Developing Llama-based RAG chatbots for government-funded conversational AI to enhance accessibility of public administration information for Jiggasha.ai
- Managing data collection team of engineers and annotators; collaborating with stakeholders to define dataset requirements and ensure ethical standards
- Producing technical documentation, research papers, and methodological write-ups
- 2022 - 2024, HCI Researcher, Design, Inclusion & Access Lab (DIAL), North South University, supervised by Dr. Nova Ahmed
- Designing Accountable and Ethical AI for South Asian Marginalized Communities: Conducted expert interviews with stakeholders across Bangladesh, India, and South Asia; performed analysis and literature review to design AI ethics frameworks and data-driven policy recommendations
- My Freedom in Light: Led fictional inquiry and co-design workshops investigating challenges of women in computing in Bangladesh
- CS Ethics of Global South: Conducted interviews with researchers and practitioners to revise ACM CS curriculum guidelines on ethics
- Alor Akash - Gender and Technology in Bangladesh: Researched gender, technology, and financial inclusion; performed text visualization and sentiment analysis of interview transcripts
- 2022 - 2023, Research Assistant, Bengali NLP: Application in Literature and Natural Language Generation, North South University, supervised by Dr. Mohammad Rashedur Rahman
- Developed answer-aware Bengali question generation models by fine-tuning Multilingual T5 and BanglaT5, achieving 95%+ on answerability, grammatical correctness, and relevancy metrics
- Conducted human evaluation and benchmarking against Hindi and Arabic models
- Mentored two junior research assistants on Bengali Visual Question Generation research
- 2022 - 2023, Predoctoral Research Fellow, Fatima Fellowship, mentored by Benjamin Muller
- Analyzed generative multilingual language models (BLOOM and XGLM) to investigate formality bias across 5 languages
- Optimized prompting techniques to reduce degenerated sentences and detect formality patterns in multilingual outputs
- 2022, AI Fellow, Pi School of AI, Rome, Italy (Remote), supervised by Sébastien Bratières
- Developed multilingual code-mixed language identification for 10 European languages in collaboration with Translated
- Trained XLM-ROBERTA model achieving competitive performance with Fasttext/Lingua on short text token-level language prediction
- 2019, Google Summer of Code, TensorFlow Hub, mentored by Vojtech Bardiovský
- Developed text embedding modules for TensorFlow Hub
- Authored tutorial on Bangla news article classification featured in official TensorFlow Hub documentation
- 2018, Google Summer of Code, Berkman Klein Center for Internet & Society, Harvard University, mentored by Hal Roberts
🎖 Honors and Awards
- 2023 Best Journal Paper Award, ACM COMPASS 2023
- 2023 Humayun Ahmed Research Fellowship, NSU HCI DIAL Lab
- 2021 Weights and Bias Fastai x Huggingface Study Group Blog Competition Winner
- 2019 Secure and Private AI Scholarship Challenge, Udacity-Facebook
- 2018 AWS Machine Learning Scholarship, Udacity-Amazon
- 2018 Fast.ai International Fellowship (Featured in Forbes and Fast.ai)
- 2017 Udacity Machine Learning Nanodegree Scholarship
⚙️ Services
- Reviewer: ACM CHI 2025 (Student Design Competition), Springer Nature Journals
- Program Committee Member Edge AI Research Symposium 2026, San Diego
💬 Invited Talks
- 2025, Speaker, “Ethics in Action: A Responsible AI Workshop”, IUB CCDS.AI (HCI Wing).
- 2024, Panelist, AI and Social Balance – The Current Landscape, ITU Punjab, Pakistan. | [post]
- 2023, Panelist, AI – Women’s Risks and Opportunities in Bangladesh, Naripokhkho.
🌍 Conference Participation
- 2025, Presenter, Workshop on Safe and Secure AI agents, The 13th IEEE International Conference on Big Data (IEEE BigData 2025).
- 2024, Presenter, Proceedings of the 13th International Conference on Information & Communication Technologies and Development, ICTD 2024, Nairobi, Kenya (presented virtually).
- 2024, Poster Presentation, South Asian AI Ethics Framework: What Values Are We Looking For?, ACM COMPASS 2024, New Delhi, India. | Poster
- 2024, Delegate, The Inaugural Conference of the International Association for Safe and Ethical AI, OECD Headquarters, Paris. | [conference]
🎤 Presentations & Reading Groups
- 2022, Sister Library: AI Poetry & Datasets, Goethe-Institut and HerStory Foundation. | [video]
- 2022, Paper Presentation, Language Models are Few-Shot Learners, NLP Reading Group Dhaka.
- 2022, W&B Study Group: fastai with Hugging Face Demo Day. | [video]
- 2021, Breaking into Research for Undergraduate Students, Free Schooling Bangladesh. | [video]
- 2020, Udacity School of Artificial Intelligence Open House. | [video]
🪄 Misc
I write about machine learning, NLP, and responsible AI.
→ Read & subscribe on Substack and Medium.