Classifying Bangla Fake News with HuggingFace Transformers and Fastai




In this post we cover fine tuning a multilingual BERT model from Huggingface Transformers library on BanFakeNews dataset released in LREC 2020. While English Fake News Classification and fact checking tasks have many resources and competitions available such as fake news challenge and hateful meme detection, similar efforts in Bangla has been almost non existent. BanFakeNews dataset contains 50k annotated articles from different news sources in Bangladesh, out of them around 1200 articles have been annotated as fake. As transformer architectures uses self attention to learn contextual embeddings they have been very popular in NLP research community for a while and many tools have been built around them.
This post is reusing materials taught in Weights and Bias's study group of Fast ai with Huggingface(link) where several recent(2021) libraries(blurr,Fasthugs & Adaptnlp) that integrates components from popular deep learning frameworks Huggingface transformers and Fastai v2 are shown.
My experience with using Transformers is fairly low, recently I participated in Huggingface's Flax/Jax week and there our team pretrained Bengali GPT2 and T5, so I was looking into Huggingface course and documentation to learn more about how to finetune transformers. Previously my thesis journal paper for undergraduate "Deep Learning based Question Answering System in Bengali" worked on Bangla Question Answering with transformers, but I had stuck more to given scripts back then and focused more on synthetic dataset construction via translation and handling data corruption issues. So this post will focus more on the high level API of Blurr and the components of huggingface and fastai that are relevant for getting started quickly.
!pip install -Uqq transformers datasets tqdm
!pip install -Uqq ohmeow-blurr
!pip install -Uqq wandb
from google.colab import drive
drive.mount('/content/drive')
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import wandb
from transformers import *
from fastai.text.all import *
from fastai.callback.wandb import *
from blurr.data.all import *
from blurr.modeling.all import *
We will use weights and biases for tracking experiments and runs. Project page : https://wandb.ai/tasmiah-tahsin/fake-news-blurr
wandb.login()
This dataset has been downloaded from Kaggle. Note that there are four files in the given dataset, but we use the two files (Authentic-48k and fake-1k) here because the rest of the files contain labelled fake and authentic news. Labelling in the sense of what type of fake news it is, clickbait, satire, misleading or false context, for the current priliminary phase we stick to binary classification of knowing if a news is fake or authentic. We also concatanate headline and content of the news article during preprocessing and combine the fake and authentic news dataset before sending them to Blurr dataloaders. This dataset is heavily imbalanced, so I'll take approximately half of the authentic news set, since taking full set takes each epoch with a batch size of four around an hour.

fake = pd.read_csv("/content/drive/MyDrive/fake news/Fake-1K.csv")
authentic = pd.read_csv("/content/drive/MyDrive/fake news/Authentic-48K.csv",engine='python',error_bad_lines=False,warn_bad_lines=True,nrows=15000)
df = pd.concat([authentic[['headline','content','label']],fake[['headline','content','label']]])
df.reset_index(drop=True,inplace=True)
print(authentic.shape, fake.shape)
df['text'] = df['headline'] + df['content']
df = df.drop(['headline','content'],axis=1)
df.head(1)
df.label=df.label.map({1:"Authentic",0:"Fake"})
from sklearn.model_selection import train_test_split
train, valid = train_test_split(df, test_size=0.2)
We will use Blurr high level API for sequence classification with the pandas dataframe where BlearnerForSequenceClassification.from_dataframe() method takes in a dataframe, splits them from the column of default is_valid using Fastai's ColSplitter into train and test splits, constructs the datablock and dataloaders and uses them for training. So we add a 'is_valid' column in the dataframe. There are other ways of splitting the data available in Fastai like RandomSubsetSplitter where we can randomize the data inside a dataframe. Since we used scikit-learns train test split to shuffle the dataframe for now we can go with Column based splitting.
train['is_valid'] = False
valid['is_valid'] = True
final_df = pd.concat([train,valid],axis=0)
final_df.shape
final_df.head()
final_df.label.value_counts()
Since the original paper also used multilingual cased bert released by Google this post can be considered as an attempt to reproduce the work of BanFakeNews. They trained mbert for 50 epochs with a learning rate of 0.00002 and optimizer Adam. The batch size was 32. The overall F1 score after training for 50 epochs on this dataset was .99 and f1 for fake class was 0.68. Multilingual bert has been pretrained on 104 languages including bengali with wordpiece tokenization. As bengali is already included it makes it a valid choice for current bangla text classification task. Information for this model are : 104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters. As the size of the language corpora varied greatly for low resource languages exponential weighted smoothing was performed for weighting data during the pretraining stage, which results in undersampling high resource languages like english and oversampling low resource languages like Bengali. Mbert does not use any marker for input language to enable zero shot training.
wandb_init_kwargs = {
'reinit': True,
'project': "fake-news-blurr",
'entity': "tasmiah-tahsin",
'notes': 'Finetuning banfakenews with multilingual bert via Blurr',
'tags': ['mbert', 'fake-news-classification', 'blurr']
}
wandb.init(**wandb_init_kwargs)
Since I'm fairly new in blurr I'm using the high level API, but the key ideas are following. blurr is integrating two frameworks. Here Fastai is providing the datablock, learner, learning rate finder functionalities with Leslie Smith's 1cycle policy components, while huggingface transformers is providing the ready to use transformer model configuration and architectures made publicly available from huggingface hub(in general terms, but huggingface also has its own datasets library which integrates well with blurr, and fastai also provides pretrained language models based on LSTM like ULMFiT and MultiFiT.
Fastai's datablock API works like a specification for quickly loading a data into a model. The blocks are specific steps which can be mixed/matched for training with its various transforms and splitting functions along with visualization capacities. Datablocks, Callbacks, and other fastai concepts are explained in the paper "fastai: A Layered API for Deep Learning". Under the hood blurr is providing wrappers for the huggingface transformers and for finetuning the parameters of the model with enabling discriminative learning rate like used inULMFiT. Discriminative learning rate refers to using variable learning rates for different layers of a network while performing transfer learning.
The low level API for blurr works with datablocks and dataloaders creating the mini batches which are combined with the huggingface model architecture, optimizer and loss function inside a learner. Mid level API contains BLearner and the highest level API contains task specific learners like the current one I'm using which is BlearnerForSequenceClassification.
from blurr.modeling.core import BlearnerForSequenceClassification
pretrained_model_name = "bert-base-multilingual-cased"
learn = BlearnerForSequenceClassification.from_dataframe(final_df, pretrained_model_name, dl_kwargs={ 'bs': 4})
learn.lr_find(suggest_funcs=[minimum, steep, valley, slide])

I initially unfreezed all the layers and had set max learning rate to 1e-2 but the results were pretty bad. So I reduced the learning rate, decided to not do full unfreezing and retrained the model again. Original model in the training set was trained for 50 epochs, here we are experimenting with only 5 epochs though. Fastai documentation recommends that we set the learning rate equal to one order of magnitude lower than the minimum, so I went with 1e-3.
learn.fit_one_cycle(5, lr_max=1e-3,cbs=[WandbCallback(log_preds=False, log_model=False)])
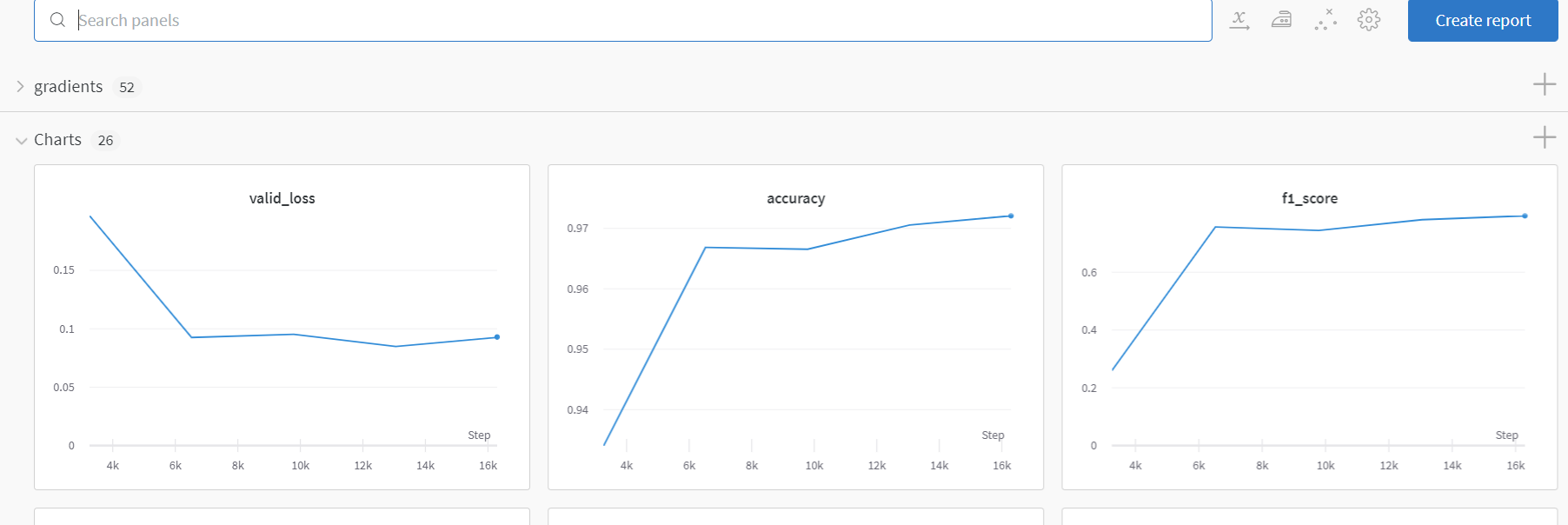
We can see some of the results by the model here. Our model trains on half of the dataset and achieves around 0.80 in overall f1. Its likely that the model is trained longer it will achieve better performance. I might retrain it later on full data.
learn.show_results(learner=learn, max_n=4,trunc_at=200)
wandb.finish()
To upload our model to Huggingface hub we can use push_to_hub method available to the models. The details can be found here. We install git-lfs since the tokenizer and the model files are fairly large. After uploading the model to the huggingface hub we will also use pipeline functionality by transformers and combine with transformers interpret library to see how the model weights each of the input tokens when making predictions in the section below.
!sudo apt-get install git-lfs
!transformers-cli login
!git config --global user.email "tasmiah.tahsin@northsouth.edu"
!git config --global user.name "Tahsin-Mayeesha"
blurr_tfm = get_blurr_tfm(learn.dls.before_batch)
blurr_tfm.hf_model.push_to_hub("bangla-fake-news-mbert",use_temp_dir=True)
blurr_tfm.hf_tokenizer.push_to_hub("bangla-fake-news-mbert",use_temp_dir=True)
Transformers interpret library tries to show weights for tokens after making predictions and make some visualizations. The tokens are split into subwords as per the tokenizer.
!pip install transformers-interpret
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name = "Tahsin-Mayeesha/bangla-fake-news-mbert"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = "অভিনেতা আফজাল শরীফকে ২০ লাখ টাকার অনুদান অসুস্থ অভিনেতা আফজাল শরীফকে চিকিৎসার জন্য ২০ লাখ টাকা অনুদান দিয়েছেন প্রধানমন্ত্রী শেখ হাসিনা।"
from transformers_interpret import SequenceClassificationExplainer
cls_explainer = SequenceClassificationExplainer(
model,
tokenizer)
word_attributions = cls_explainer(text)
word_attributions[0:10]
cls_explainer.visualize()

Resources
- fastai paper : https://arxiv.org/pdf/2002.04688.pdf
- https://github.com/ohmeow/blurr
- fine-tuning mrpc with blurr colab
- weights and biases study group of fastai x huggingface playlist
- multilingual bert
- https://github.com/cdpierse/transformers-interpret
- https://blog.dataiku.com/the-learning-rate-finder-technique-how-reliable-is-it